


I’ve been working on an acrolinx IQ deployment for my employer Oracle (yes, I do have a real job). For many who go down this route, the claim that such initiatives are only being done because it will mean the instant arrival of machine translation (MT) will seem familiar.
The ‘translation process’ imperative is the wrong way to drive such initiatives. Instead, what is critical here is understand the notion of managing information quality for the user, regardless of the translation process. Because the language used in content, or information if you like, is a user experience (UX) issue.
It’s clear that a quality input (or source) gives better returns for every kind of translation. In the case of any language technology, clean source data delivers the best returns; and is becoming even more important as more and more turn to statistical machine translation.
Furthermore, the points made by Mike Dillinger at the recent Aquatic/Bay Area Machine Translation User Group meeting need re-emphasizing: MT does not require special writing; people require special writing. The rules for writing English source text for human translators, machine translators, and users in general, are the same.
Developing quality information in the first place, and then managing it, is the way to go.
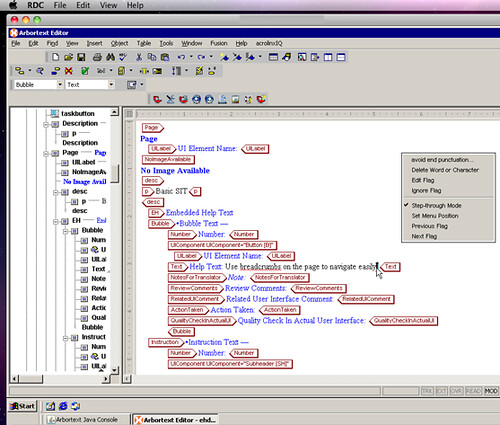
So, forget about “controlled authoring” (manual, automated, or whatever other method of implementing it) and indeed “writing for translation” classes as the “mandatory prerequisite” for improved translatability or machine translation. Think and practise information quality as an end user deliverable in itself that has significant translation automation (and other) externalities.
I’d love to hear other perspectives on this, too.
If you’re interested in this notion of the primacy of information quality per se in the translation space, then read Kirti Vashee’s The Importance of Information Quality & Standards.


{kind=link}